



High‑Velocity AI‑Native Quality Engineering
As enterprises rapidly adopt innovative and agile systems, traditional QA and testing approaches are no longer sufficient. Unlike traditional solutions, today’s enterprise solutions behave probabilistically—producing variable outputs, invoking tools autonomously, and executing multi-step reasoning chains that cannot be validated through simple pass/fail assertions.
Happiest Minds’ GenAI QA Services are a set of AI‑native Quality Engineering services designed to assure the accuracy, safety, reliability, and governance of enterprise systems across their full lifecycle—from RAG-based assistants to fully autonomous multi-agent workflows.
Why Enterprises Need Improved Quality Engineering Model
01
QA teams devote 70-80% of their time to manually chase creating test cases instead of focusing on validating real outcomes.
02
Traditional TA approaches lag a dependable framework to verify that AI outputs are accurate, unbiased, safe, and aligned with business.
03
Current processes lack a systematic way to generate diverse prompt styles, including casual, urgent, adversarial, and multi-persona inputs.
04
There is a rising demand for AI to plan, invoke tools, and execute complex, multi-step workflows within enterprise environments.
05
Organizations face growing pressure to scale GenAI safely or risk being outpaced by competitors who are doing so responsibly.

What We Validate Under GenAI QA Services
01
RAG‑based knowledge assistants
02
Multilingual AI chatbots
03
Prompt‑driven GenAI workflows
04
Agentic AI systems with tool invocation and reasoning paths
GenAI QA Frameworks & Accelerators

Test Foundry
Intelligent test case and Q&A generation platform that transforms enterprise documents into high-quality golden datasets for RAG and Gen AI validation.

GenAI Response Quality Bench
A comprehensive multi-dimensional evaluation framework that put forth structured, objective, and auditable quality assessments across key dimensions including Accuracy, Relevance, Faithfulness, Coherence, Toxicity and Bias

Prompt Craft
Advanced prompt variations engine for generating diverse test data and prompt variations across tone, persona, context, and user intent.

LLM Litmus
Evaluate and compare selected LLMs using objective quality scores across key performance dimensions such as accuracy, relevance, faithfulness, latency, and safety.

Agent Trace
Agent Execution Validation Framework designed to validate reasoning flows, tool interactions, decision paths, and execution integrity in agentic AI systems.
QA Lifecycle for Generative AI Testing
Traditional QA vs GenAI QA Frameworks
| Traditional Testing | Happiest Minds GenAI QA Frameworks | |
|---|---|---|
| Deterministic assertions (exact match) | Semantic and probabilistic quality evaluation | |
| Manual test case authoring | AI-automated test generation from source documents | |
| Fixed input/output testing | Multi-tone, adversarial, and diverse prompt coverage | |
| Single-system testing | Multi-model benchmarking and comparison | |
| Functional pass/fail only | Multi-dimensional scoring: accuracy, bias, toxicity, coherence | |
| No agent trace analysis | Full execution trace validation with 6 behavioral metrics | |
| No drift detection | Continuous model drift and regression monitoring |
GenAI QA Tools & Technology
-

Generation
Test Foundry
-
Variation
Prompt Craft
-
Synthesis
Synthetic Data Generator
-
Scoring
LLM Quality Evaluator
-
Safety
AI Judge & Guardrails
-
Automation
Continuous QA Pipeline

Efficiency at Scale: Outcomes of Gen AI QA Implementation
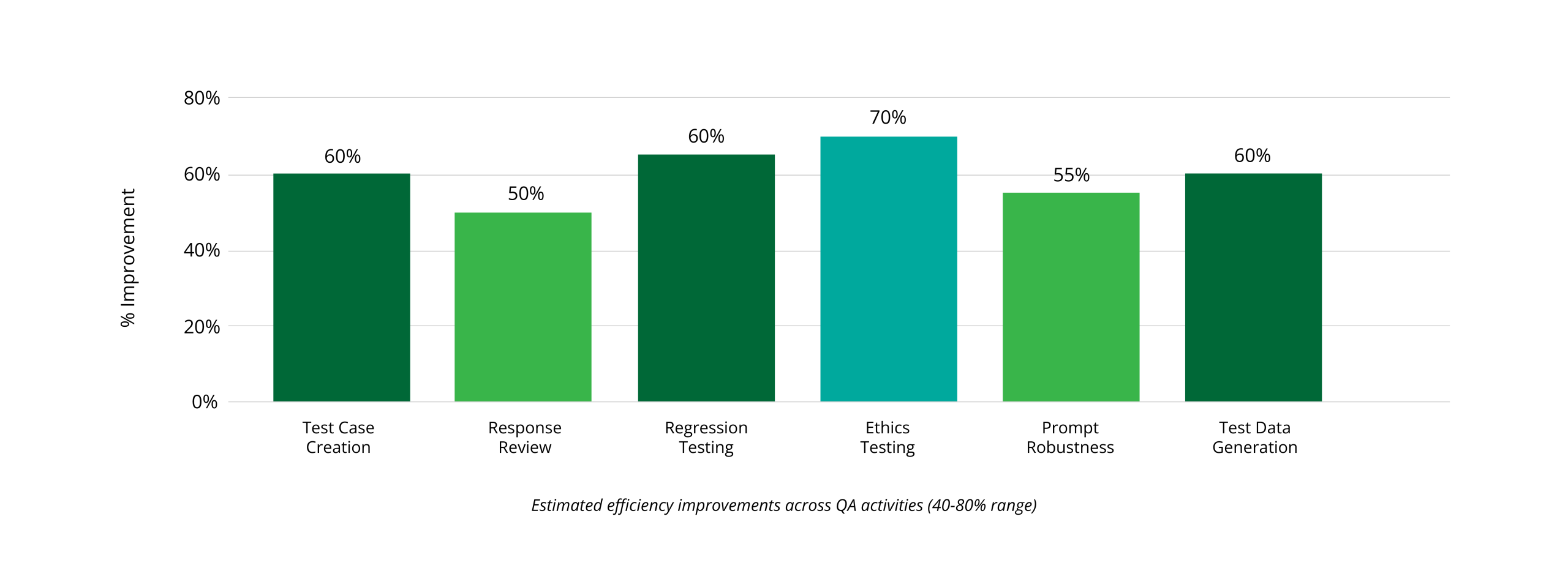
GenAI QA Impact Across the Enterprise

Help stakeholders quickly drive innovation from pilot to scale.

Enable QA & engineering leaders modernize validation.

Empower risk, compliance & responsible AI teams.

Strengthen product teams to deliver customer‑first experiences.
Related Generative AI Services

Gen AI Services

Agentic AI Services

Intelligent Automation

Data Engineering & Analytics
Cloud Modernization

Digital Product Engineering
Frequently Asked Questions
GenAI QA is an AI‑native approach to quality engineering that validates AI‑driven responses, decisions, and actions—not just code correctness. It ensures existing systems as well as Generative and Agentic AI systems produce accurate, safe, unbiased, and trustworthy outcomes across enterprise workflows, including systems layered on existing platforms.
Traditional QA relies on deterministic pass/fail checks and manually written test cases. GenAI QA validates probabilistic behavior, multi‑step reasoning, tool execution, and evolving AI outputs. This makes it essential for AI‑augmented enterprise systems where the same input may produce different outcomes.
Yes. Even when core enterprise systems remain unchanged, adding GenAI or Agentic AI introduces new risk layers—such as hallucinations, incorrect retrieval, and partial agent execution. GenAI QA ensures these AI‑driven layers behave correctly and do not compromise business outcomes or trust.
GenAI QA supports a wide range of enterprise use cases, including:
1. RAG‑based knowledge assistants
2. Enterprise chatbots and copilots
3. Prompt‑driven AI workflows
4. Autonomous and Agentic AI systems executing multi‑step tasks
These systems require continuous validation as models, prompts, and data evolve.
By automating test generation, response evaluation, and regression baselining, GenAI QA reduces manual validation effort by 40–60% while increasing test depth and coverage. This allows enterprises to release and scale AI faster—without sacrificing quality or governance.
GenAI QA should be implemented as soon as AI influences enterprise decisions or actions—not just before production. Early adoption enables safe scaling, faster innovation, and confidence as AI‑native development accelerates across smaller, AI‑augmented teams