
This blog is intended for data engineers, data scientists who are planning to use Spark & Scala, and for anyone who is interested in learning Spark trough practice.
Understanding How to use Spark for Data Exploration
The goal of the blog is to provide a quick start to Apache Spark and how to go about its application
- RDD
- Transformations
- Actions
- Perform Joins
- Spark SQL
- Spark Automatic Json Schema Inference Capability
- Caching
- Lazy Evaluation
Quick Intro to Spark
Apache Spark is often referred to as the ‘Swiss Knife’, because of its ability to do different tasks with ease. It can handle data cleansing, data exploration, feature extraction, sql query, machine learning, complex graph algorithms, building streaming applications, etc…
Getting Started with Spark
In case you do not have a spark setup on your machine, do not worry. It takes less than 2 minutes to get started. Download spark from “Apache Spark”. Extract it and start the Scala REPL from $Spark Home/bin/spark-shell.
Note:- $Spark_Home is the location where you extracted.
Loading Data Set
Download the required Data Set from github repository and execute the below steps in the spark-shell.
valrawData = sc.textFile(“path/usagov_bitly_data2012-03-16-1331923249.txt”)
rawData: org.apache.spark.rdd.RDD[String] = usagov_bitly_data2012-03-16-1331923249.txt MappedRDD[1] at textFile at :12
We just created an RDD called raw data.
What is RDD : In simplest words, it can be expressed as a data structure distributed across many machines. RDD is the core of Spark, and all operations revolve around it.
Spark provides two kinds of operations, one is transformation and another is action.
Transformation and Actions
What is Transformation: Transformation converts one RDD to another RDD.
What is Action: Action on the other hand produces an output like printing the data and storing the data .
In this case, we created an RDD of type string.
What is sc: For Spark shell , Spark creates a context sc. It is the main entry point for Spark functionality. It helps you tcreate RDD, accumulate and broadcast variables.
What is Text File: Text File method helps you read data from local file system, Hadoop file system or any hadoop-supported system URI.
Before proceeding further, Let’s try to understand about the data set.
In 2011, URL shortening service bit.ly partnered with the United States government’s website – usa.gov to provide a feed of anonymous data gathered from users who shorten links ending with .gov or .mil. Each line in each file contains a common form of web data known as ‘JSON’ .
So one of the key points is, we are going to deal with JSON data, and each line in the file represents a JSON input.
Let’s try to see what our RDD contains. Spark provides methods like collect, take(number of records), first to access the elements in the RDD.
Collect() : It brings the entire data to the driver program. In our case, driver program is Spark Shell. You cannot collect when the data set is huge, that it cannot fit into the memory of a single machine. You can use and collect the same when your dataset is limited.
Take(n) : It complements the limitation of collect. It returns the n elements of the RDD.
First : It returns only one element from the RDD. Useful when you want to quickly check whether your operations worked correctly.
Let’s try first on our rawData. “rawData.first”
res0: String = { “a”: “Mozilla\/5.0 (Windows NT 6.1; WOW64) AppleWebKit\/535.11 (KHTML, like Gecko) Chrome\/17.0.963.78 Safari\/535.11”, “c”: “US”, “nk”: 1, “tz”: “America\/New_York”, “gr”: “MA”, “g”: “A6qOVH”, “h”: “wfLQtf”, “l”: “orofrog”, “al”: “en-US,en;q=0.8”, “hh”: “1.usa.gov”, “r”: “http:\/\/www.facebook.com\/l\/7AQEFzjSi\/1.usa.gov\/wfLQtf”, “u”: “http:\/\/www.ncbi.nlm.nih.gov\/pubmed\/22415991”, “t”: 1331923247, “hc”: 1331822918, “cy”: “Danvers”, “ll”: [ 42.576698, -70.954903 ] }
Spark SQL JSON Inference
To understand more about the data set, we should bring JSON data to a structured form like table. For that, we need to extract the elements . There are several JSON libraries which can help in parsing data. We will use Spark Sql capability of inferring JSON Schema to structure our data.
import org.apache.spark.sql.SQLContext
valsqlContext = new SQLContext(sc)
valrecordsJson = sqlContext.jsonRDD(rawData)
recordsJson.registerTempTable(“records”)
SparkSql is a subproject of Apache Spark to deal with structured data. The beauty of it is that it works seamlessly with Spark programs. It provides various features to handle data from Hive, JSON , parquet and thrift service for external programs to connect. There are many more features that Spark SQL supports.
Lets try to check what is the schema of our data. SparkSQL comes with a printSchema method.
recordsJson.printSchema
root
|– _heartbeat_: integer (nullable = true)
|– a: string (nullable = true)
|– al: string (nullable = true)
|– c: string (nullable = true)
|– cy: string (nullable = true)
|– g: string (nullable = true)
|– gr: string (nullable = true)
|– h: string (nullable = true)
|– hc: integer (nullable = true)
|– hh: string (nullable = true)
|– kw: string (nullable = true)
|– l: string (nullable = true)
|– ll: array (nullable = true)
| |– element: double (containsNull = false)
|– nk: integer (nullable = true)
|– r: string (nullable = true)
|– t: integer (nullable = true)
|– tz: string (nullable = true)
|– u: string (nullable = true)
One advantage of SparkSQL is that we can use the spark functionalities also. Now let’s try to proceed with our exploration of the dataset. Let’s take one particular field say ‘tz‘ which stands for time zone. Lets quickly write a SQL to extract the data.
val x = sqlContext.sql(“select tz from records”)
Now, ‘x’ will contain only the time zone records.
Lets try to find how many times each time zone occurs in the data set
How can we solve it. Let’s get each element, and then map it to 1 to form a key value pair.
x.map(row => row(0)).map(temp => (temp,1))
Here x is a Schema RDD.
map(f): map is a transformation applied on the RDD . It accepts a function as input, and applies it to each element of RDD in a parallel fashion.
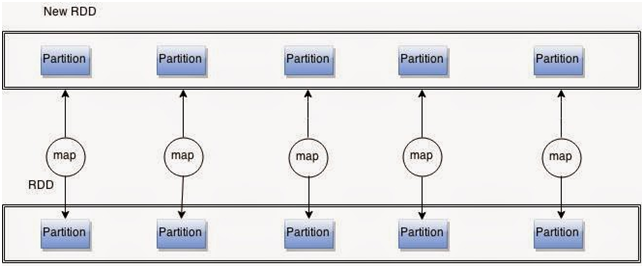
Let’s see how the elements have transformed . We will do take(5) on the above RDD .
(America/New_York,1)
(America/Denver,1)
(America/New_York,1)
(America/Sao_Paulo,1)
(America/New_York,1)
Now, a simple question that you can be asking yourself could be ‘why I am pairing each field with 1?’. Basically we converted our fields to a tuple of key-value pairs.
Spark provides useful transformations on key-value pair RDD like reduceByKey ,groupByKey , countByKey and many more.
Let’s get back to our question, how many times each time zone occurs . Hope you would have guessed it, let us use reduceByKey on the data.
x.map(row => row(0)).map(temp => (temp,1)).reduceByKey((x,y) =>x+y).take(5).foreach(println)
(null,120)
(Europe/Brussels,4)
(Europe/Vienna,6)
(Europe/Athens,6)
(America/Puerto_Rico,10)
Note: Remember that transformations in Spark are Lazy, it means till you perform an action like count ,first, collect, saveAsTextFile transformations are not evaluated.
Looking at the result , we can recognize that there are null values . Let’s try to remove records that contain nullvalues. Spark comes with a handy filter method.
x.map(row => row(0)).filter(x => x!=null).map(temp => (temp,1)).reduceByKey((x,y) =>x+y).take(5).foreach(println)
(Europe/Brussels,4)
(Asia/Bangkok,6)
(Pacific/Honolulu,36)
(America/Santo_Domingo,1)
(Europe/Bucharest,4)
Let’s see how we could sort the data. We will use sortBy .
x.map(row => row(0)).filter(x => x!=null).map(temp => (temp,1)).reduceByKey((x,y) =>x+y).sortBy(_._2,false).take(5).foreach(println)
(America/New_York,1251)
(,521)
(America/Chicago,400)
(America/Los_Angeles,382)
(America/Denver,191)
Looking at the data , we can guess that the data needs more cleansing, which I will leave to you.
Use the filter() on the RDD and remove the empty rows.
We can simplify the entire task by writing a SQL query on records table .
sqlContext.sql(“select tz,count(tz) as total from records where tz != ” and tz is not NULL group by tz order by total desc”).take(5).foreach(println)
[America/New_York,1251]
[America/Chicago,400]
[America/Los_Angeles,382]
[America/Denver,191]
[Europe/London,74]
In the next blog we will look into how joins, caching, lazy evaluation works.

Vishnu is a former Happiest Mind and this content was created and published during his tenure.



