
Analytics has become important for every business to run successfully. Understanding your customer’s requirement, predicting what they want at the right time has become more and more important. Time to react has become the key to success for many business lines, particularly for the e-commerce, automobile, healthcare, advertising industry and others. Data being gold for the business has to be mined as it comes in. Gone are the days where you mine data to find HISTORICAL INSIGHTS.
ACTION BASED INSIGHTS need to take place in real-time to make meaningful impacts.
We will explore a set of tools that have been successfully used across the industry to implement a system that helps business to ingest actions based on data in near real-time.
The present day business challenges:-
- Huge volumes of data and a variety of data, making it difficult to process using traditional systems.
- Large number of tools are available. Hadoop, Map-Reduce, Hive, Pig, Impala, Drill, SparkSql, Cassandra, MongoDB, Hbase, Spark, Storm, Spark Streaming, Flume ,kafka, Mahout, Mllib, Oryx and the list goes on. What should we choose from the above to build a successful platform?
- Involves a huge talent pool to address / build the system as there are a lot of dependencies between different systems.
- Making the analytics available on time using the right streaming framework.
Possible Solutions:
- Using a technology stack which has a common platform and different abilities to solve my business problem, by providing a way to stream, process and analyze the data with a little learning curve for the developer teams, thus reducing the cost to the business.
- Spark provides exactly what we want by providing a better map-reduce implementation, richer functionality, support for machine learning, streaming and ease to implement in three different and powerful languages, which are java, scala, python.
- There is a tough challenge over the NOSQL area. Cassandra is a clear winner and has tight integration with apache spark.
- Kafka perfectly fits today’s real world streaming applications by providing scalability, data partitioning and ability to handle a large number of diverse consumers, all which is currently used across various companies.
Sign-off Note:
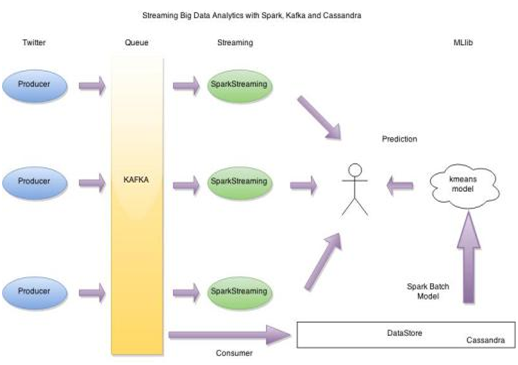
We will be watching where these technology fits in to build a streaming model that resembles the architecture required to solve the above business problem. Our model will follow the below architecture:

Vishnu is a former Happiest Mind and this content was created and published during his tenure.




