
The key aspect covered in the first part, was the journey of data to Big
Data: Big Data Analytics Practice – Part 1
This second part, would essentially try and cover the contemporary Information Management and Analytics landscape that has started to take shape and evolve in the last few years where Big Data Analytics has moved on from being experimental Proof of Concept engagements to truly complement traditional DWBI & Analytics systems and at times even replace them completely as well and become the bedrock for building Artificial Intelligence / Cognitive Computing platforms.
It is however critical to establish a perspective about Big Data & Data Science and why it will become more critical in the coming years.
What is Humongous about Big Data ?
The following events took place from around the beginning of 21st century.
Internet, Web and Social Media explosion….
- Internet Penetration is growing globally and nearly 50% of the world population would be connected to internet by 2016. This would mean around 3.2 billion internet users in 2016 with over 60% coming from developing nations. Globally 2 billion users use social network sites
- Indian Internet users have in 2016 crossed 450 Million and has surpassed US internet user numbers to become the second largest internet user population after China which has 720 Million internet users
- WordPress (2003), a free and open source Content Management System, based on PHP & MySQL, can host 50,000 new sites every day and claims to power 25% of the Internet. It has 400+ million people viewing more than 15+ billion pages each month. Its users publish about 40+ million new posts and leave 60+ million new comments each month
- Worldometer estimates over 4 Million Blogs written in any given day !! This includes blogs in WordPress, Blogger, Tumblr, Typepad, Posterous, etc.
- Wikipedia/Wikimedia (2001) has over 5 million content articles, over 38 million pages and almost a million uploaded files with over 27 million registered users including 1300+ administrators
- LinkedIn (founded in 2002) has over 400 million registered users from over 200 countries and with around 40 million students. Around 35 billion member page views happened in Q2 2015
- Youtube (2005) has around 1.3 Billion Users, with around 5 Billion videos being watched every day; More than half of Youtube views are from mobile devices and 80% outside US. YouTube has around 300 hours of video being uploaded every minute, and this could grow to over 1500 hours of video uploaded per minute (around 2 exabytes of video data per year) by 2025
- Facebook (opened to public in 2006) has around 1.6 Billion users with over 820 Million “Mobile Only Users”. Around 4.5 billion “likes” are generated daily. Just a couple of years ago, FB data warehouse stored over 300 Peta Bytes of Hive data, with an incoming daily rate of about 600 TB data
- Twitter started in 2006 and has over 330 million active users and generates 500 million tweets/day, each about 3 kilobytes including metadata. There is a projected growth to 1.2 billion tweets per day (1.36 petabytes/year) by 2025. Over 85% of twitter users are on mobile devices
- Pinterest (2010) has around 70 million users with over 80% purchasing a product they pinned
- Instagram (2010) has over 300 million users with over a billion photographs uploaded. 70 million photos and videos are added daily
- Google Plus has over 350 million users with around 20 million unique mobile monthly users and the +1 button hit 5 billion times per day
* The above are only some of the key web and social websites and statistics about their data.
The Smartphone Revolution…..
- Globally there are around 7 Billion Mobile device subscribers and mobile broadband penetration would be around 50%
- While IBM Simon, considered the first smartphone was launched in 1994, it was after Apple launched iPhone in 2005, that the smartphone adoption started to increase and currently there are around 1.5 Billion smartphones and it is projected that a third of the world’s population would have smartphones by 2017, around 2.7 Billion smartphones
- India has 75% Mobile Penetration of which Smartphones are around 20%. Adoption of 3G/4G technology in 2016 is expected to accelerate with an average indian spending around 7 hours a day in internet
- Niantic’s PokemonGo, the biggest mobile game ever (location based augmented reality game), has around 21 million active daily users beating Candy Crush and Snapchat
A few other digital milestones…..
- Online buying is estimated to be around 2.4 Trillion USD by 2018
- Amazon itself has around 60 million active customers and stores over 50 terabytes of data
- Social media marketing is used by almost 90% of US companies and accounts for around 5 % of the total web traffic
Other growing data sources….
- World data center for climate has 220 terabytes of web data and 6 petabytes of additional data
- The National Energy Research Scientific Computing Center has 2.8 petabytes of data, operated by 2,000 computational scientists
- Telecom companies like AT&T has over 323 terabytes of information and 1.9 trillion phone call records. Sprint has 2.85 trillion database rows with 365 million call detail records processed per day. At peak there are 70,000 CDR (Call Detail Record) insertions per second
- Google has over 90 million searches per day and accounts for over 50% of all internet searches
And then the Internet Of Things (IOT) / Machine 2 Machine…
- IOT is expected to connect over 28 Billion things by 2020 with wearables growing with a CAGR of over 40% in next 5 years with a market of 300+ B $ including Industrial IOT (Connected Vehicles, Industry 4.0, Smart Cities, Retail Automation, etc.) and Consumer IOT (Health & Fitness Monitoring, Home Automation). Sharing my earlier write-up about IOT and M2M : https://www.linkedin.com/pulse/iot-m2m-simplifying-smart-code-sreejit-menon?trk=prof-post
- Genomics needs to store around 40 Exabytes per year
- Astronomy: The Australian Square Kilometer Array Pathfinder (ASKAP) project currently acquires 7.5 terabytes/second of sample image data and is estimated to grow to 750 terabytes/second which would be around 25 zetta bytes per year by 2025
In what scenarios does big data make sense?
It’s important to define what truly is a Big Data Analytics scenario. There have been quite a few point of views, but in general most organizations see Big Data primarily as a data volume related challenge, but that is not the best use case for implementing Big Data
In general Big Data makes sense for scenarios where the solution needs to solve at least all the 3 Vs, namely Volume, Velocity and Variety.
If the challenge is just around volumes, databases like SQL Server, Oracle, etc. can be migrated to appliances like IBM Netezza, SAP HANA, EMC Greenplum, etc. Teradata DW Appliance can store over 54 PB of data and Teradata Active Enterprise Data Warehouse over 94 PB of data. Most Large and Mid sized Retailers were primarily using Teradata with the combination of MicroStrategy and SAS for DWBI & Analytics
But Appliances are expensive and hence the alternative could be to move to powerful object-relational database systems like PostgreSQL which can support unlimited database size including 32 TB table size, 1.6 TB Row Size and 1 GB Field sizes with unlimited indexes per table. This would however need good amount of technical expertise.
If it’s about velocity, there are Enterprise Application Integration (EAI) solutions that have been available for over a few decades that are real-time / near real-time, leaders in this segment being TIBCO, IBM, Oracle, etc. Event series analysis and event correlation engine or complex event processing engines like Esper are a popular open source alternative.
In general, the following real time (or near-real time) ETL approaches can be adopted:
- Microbatch ETL (Frequency of the batch is increased, usually to an hourly refresh) with change detection using
- Timestamps
- ETL Log Tables (Triggers in the OLTP environment)
- DBMS Log scrapers
- Network sniffers
- Enterprise Application Integration (EAI)
- Source -> Source Adapter -> Broker -> Target Adapter -> Target
- Capture, Transform, Flow
- Enterprise Information Integration (EII)
When it comes to variety, there are content management solutions that work with variety of data including documents, audio and video, etc. There are solutions that can work with multi-structured (structured, semi-structured as well as unstructured) data.
Techniques like Natural Language Processing (NLP) using enterprise Text Mining software from SAS, SPSS, etc. or open source software like Python Natural Language Tool Kit, Apache OpenNLP or Stanford CoreNLP enable analyzing Text to a large extent and are commonly used to extract features, derive sentiments, etc. IBM Watson, a cognitive platform, currently offers around 15+ APIs including Alchemy, Speech to Text and vice versa, Tone Analyzer, etc. Unstructured Information Management Architecture (UIMA) is a popular framework for Content Analytics
It is however in solving all the problems combined together (volume, velocity and variety) where and when Big Data Analytics platforms make a lot of sense. Typically with volumes greater than at least 1 TB of both transactional as well as digital (social + others) data sources and the need for real or near real-time analytics to start with would be a good thumb rule.
What constitutes Big Data ?
By and large Big Data is one or a combination of the following in a Data Lake or EDW + Data Lake formation:
– Apache Hadoop Framework / Ecosystem (Open Source) and its enterprise distributions from Cloudera, Hortonworks, MapR, Mirosoft Azure HDInsight, etc.
– NoSQL (Not only SQL) Data Storage
- Document Databases like MongoDB, RethinkDB, ArangoDb, etc.
- Graph databases like Neo4j, AllegroGraph, OrientDB, InfiniteGraph, etc.
- Columnar databases like Apache HBase, Apache Cassandra, Apache Kudu, Cloudera Impala on Hadoop (Parquet file format, a columnar storage)
- KVP databases like Redis DB, Voldermort (LinkedIn), RocksDB, etc.
- Stream databases like EventStore : An open-source, functional database with Complex Event Processing in JavaScript
– NewSQL Databases like TokuDB, Akiban, Drizzle, etc.
– Blockchain, a distributed database, used as the public ledger for bitcoin transactions. A community edition is BigchainDB
– Appliances (Hardware + Software in a box) like IBM ure Data, IBM Netezza, Aster Data from Teradata, Oracle Exadata, EMC Greenplum, HP Vertica, etc. were earlier considered the next option once standard enterprise databases like Oracle, DB2, SQL Server etc. became hard to manage with exponentially growing data volumes.
Appliances which were mostly following a MPP architecture, were also known for features like Polymorphic Data Storage, in-database compression, multi-level partitioning, in-database analytical functions, workload management, in-memory analytics, query prioritization / optimization, fast installation and configuration (mostly up and running in just hours), self healing fault tolerance, interoperatability and in general High Performance, Scalability, Availability and Reliability
There are distributed big data analytics frameworks like SPARK and Apache Flink that many organizations are currently implementing or experimenting with. These frameworks have a SQL library like SHARK/Spark SQL or Table, a stream processing API and library, a Machine Learning library and a Graph processing API and library.
Adoption of Big Data……
Industries that are leading the Big Data Adoption are Healthcare, Retail, Education, Utilities, BFSI and Media while other like Manufacturing, Travel & Transportation and Public Sector have also started to invest driven by IoT and M2M initiatives
One of the top challenges for organizations to adopt Big Data is determining the use case on how to derive value and determine ROI from a Big Data Analytics implementation.
Other organizations are concerned around risk of adoption, especially security, given that they manage end customer or high confidential data (as in the case of governments, defense, etc.) but given the advancement of Cloud and Big Data solutions like Apache Accumulo which extends the Bigtable data model to implement cell level security, there is very less that needs to be worried about, provided the right technology/tool stack and configuration is implemented
While Big Data, and Data Science on top of it, is positioned at times with the use case of needing to manage Image, Audio and Video Files in future, the truth of the majority of implementations, specially around Retail, e-commerce and BFSI industries is that the data being moved into Big Data platforms are mostly transaction data, web and/or mobile (clickstream) data, social media data, log data, sensor and location data and in some cases additional sources like emails, documents, mobile app data, etc.
Also, some organizations experience challenges in building, nurturing and retaining talent in Big Data Analytics which essentially has 4 categories of skills. Knowledge of Hadoop ecosystem and related tool sets like Hive, Pig, etc. is no longer niche but skills necessary to architect/design and build near real-time and streaming analytics platforms requires certain levels of exposure and maturity
What kinds of Big Data Analytics Initiatives are being undertaken ?
Most of the Big Data initiatives being implemented have a strategy to either achieve outcomes of enriched Customer Experience (including personalized next best actions and recommendations) or enhanced Business Efficiency or both and are mostly around the following areas:
- Social & Sentiment Analytics
- Digital / Web / Mobile Analytics including Clickstream Analytics and mash-up with Transactional Data for enriched customer and marketing analytics
- User Behavior, Viewership and Content Analytics
- Augmenting Enterprise Data Warehouses with Multi-structured Data Management
- Migration from EDW or DW Appliances to a Big Data Lake, many-a-times for reduced cost of ownership / licensing as well as in preparation to be able to manage newer data types in future and to enable streaming Analytics
- IoT / M2M Analytics platform development
- Cloud Based Big Data Analytics platforms and solutions
- AI and Cognitive Platform development like IBM Watson, IPSoft Amelia, Apple Siri, Google Tensor Flow & Google Now, Microsoft (the underdog) Cortana, Tay Chatbot, Malmo and Azure Machine Learning, etc.
In some industries like Retail, most of the Big Data Initiatives still involve migration of the structured transaction data along with Clickstream data to get a combined view of the customer behavior both in-store as well as online.
What are some of the industry wise Big Data Analytics use cases ?
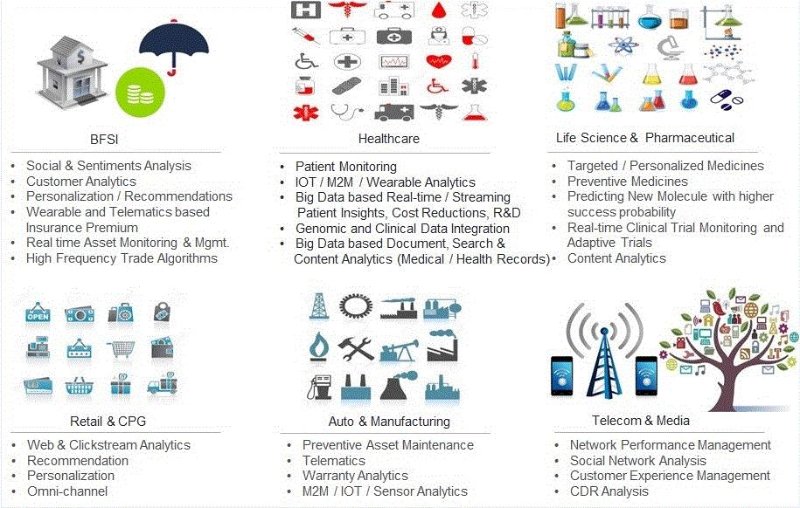
Why some enterprises are still not considering harnessing their data for competitive advantage?
Many enterprises do not still consider Data as a strategic Asset and hence do not have a clear strategy for monetizing their Data and at times the amount of data that these organizations may be generating or would in coming years or at times already have present over years in multiple siloed stores is humungous.
There needs to be an enterprise wide Data Strategy initiative supported or anchored along with key Business Stakeholders for developing a roadmap and execution plan for the same including MDM and Data Governance programs to enable the larger objectives. Many organizations hence now have roles like the Chief Data Officer. This shouldn’t be confused with Chief Digital Officer whose role would at times have an overlap, but is clearly set for a different objective, more towards enhancing customer experience across multiple channels and customer journey touch-points
Big Data with and without Data Science ? Data Science without Big Data ?
Technically speaking Big Data is the augmented or replacement Information Management layer that provides the platform for Data Science / Advanced Analytics to be performed.
Quite a few Big Data Visualization and Big Data Analytics platforms and products, both on premise as well as on cloud, are now available with custom industry and cross-industry solutions out-of-the-box.
Many are still frameworks and can be used to accelerate the Big Data implementation. However Big Data Analytics is mostly an initiative that combines implementation of Big Data (Hadoop Ecosystem with or without NoSQL and others) with Data Science / Machine Learning / Advanced Analytics and thereafter Visualization on the top, consumable over mobile and other devices, channels, formats, etc.
There is still a lot of traditional analytics being done and consumed that has nothing yet to do with Big Data as such, as in the Pharma and Life Science Industry for example, but there are changes taking place there and with all industries as well in terms of Big Data Analytics adoption.
The concepts of Calculus, Probability, Correlation and Regression, Least Squares, Time Series, Bayes Theorem, Matrices and Generalization, Fourier and other Transforms, Hypothesis Theory, Design of Experiments, Optimization Methods, etc. existed before mid of last century and while the basic techniques and applications of Analytics, be it descriptive, predictive or prescriptive, more or less remains the same even on Big Data, traditional Analytics used technologies like SAS and SPSS and was more of a GUI supported Drag-Drop-Configure based Analytics (with exceptions of the programming interfaces that SAS, SPSS and others provided), with open source alternatives like R / RStudio and enterprise versions like Revolution Analytics (acquired by Microsoft)
Big Data however needs more scalable and compatible analytics algorithm / model development and involves code development in Java, Python, Scala, etc. with use of Machine Learning libraries (Java based libraries like Mahout, SparkML, Weka or Python based libraries like NLTK, Pybrain, Pylearn, MDP) apart from others like H2O, Shogun,Vowpal Wabbit, etc.
* Programming languages in general that are getting popular include Swift, C++11, Rust, Go, Clojure, F#, Haskell, C#, Ruby & Ruby on Rails, etc.
Once implemented, what are the best practices to make Big Data continue to work for an organization?
To make Big Data work for an organization and ensure that the ROI on the implementation is met, it is critical that increased measurable insights are generated and enabled through Data Science / Advanced Analytics on top of the Big Data platform with the larger objectives of improving customer experience impacting positive revenue growth and/or improved business efficiency.
Some of the “post implementation” Best Practices involve:
- Ensure continued Improvement of the Data Ingestion and Processing layers. Implementation of wrong architecture would have an impact on the ability to truly consume the insights within the opportunity time-window as in the example of Personalization and Recommendations
- Ensuring a Data governance framework is enabled for the new data that is now available along with the erstwhile enterprise structured data to enable enriched insights. There are platforms and products evolving in this space as well like IBM InfoSphere Big Match
- Ensure continued alignment to the Enterprise Cloud Strategy, if any
True success is when Big Data helps enable higher Automation and /or in developing Artificial Intelligence that stands to provide a long-term benefit and not just meet short term goals and hence it should be part of a larger Data Strategy and Insights Roadmap.
What is the near future for Big Data Analytics ?
There is the cyclical pattern in the information management products and services space in terms of going from IT and programming intensive, data and information management systems to more business oriented, self service and rich UI and metadata driven systems and platforms, and then again circling back to IT and programming based storage, data management and information processing systems for managing faster, newer and unstructured data sources, and in case of Big Data, once again in file systems while now adopting massive parallel processing. This perhaps in conjunction to the EDW, BI, Visualization and Analytics landscape, already functional in an enterprise
Big Data Analytics & Visualization platforms like IBM BigInsights, HP HAVEn, Teradata Integrated Data Platform (Unified Data Architecture), etc. and products like Datameer, Platfora, Lumify and industry specific ones like Palantir, Ayasdi, etc. as well as others like Lucidworks (Search and Analytics platform) are proprietary solutions that organizations are evaluating after initial tinkering with open source
To be Continued………In the next blog, the focus would be on what it takes to run a Big Data Analytics practice, now that the technical breadth and depth in this space has been established.
* Credits: Research for this blog includes reports from Gartner, Nasscom, Wiki apart from online research
* The image used in the cover of this blog is courtesy of the respective artist

Sreejit has over 22 years of IT experience in Digital and Analytics leadership roles. Having setup the Digital Analytics Practice for Happiest Minds, Sreejit currently reports into Happiest Minds Executive Board (2 CEOs) for Strategic Accounts and Alliance Leadership. He is responsible for developing Strategies, Leading Alliances & Partnerships, Sales, Solutions Development & creating Non Linear Revenue Growth, Account Mining, and People Management. Sreejit is a B.Tech in Computers, a PMI certified Project Management Professional and has completed an Executive Management Program in Sales and Marketing from the Indian Institute of Management, Lucknow.





