
Introduction: Data as the Foundation of Intelligent Networks
Enterprise network automation has evolved from scripted command execution to policy validation engines, compliance pipelines, and increasingly, AI-assisted operations. Yet as environments scale, many organizations discover that automation maturity is not limited by tools — it is limited by data architecture. In the era of AI-driven intelligence, automation is only as strong as the data ecosystem behind it.
Modern enterprise networks generate vast volumes of configuration states, telemetry metrics, logs, and operational events. Collecting this information is straightforward. Structuring, optimizing, governing, and preparing it for analytics and AI consumption is the real engineering challenge. Scalable automation begins with disciplined data design.
The Scaling Problem: When Data Becomes Technical Debt
At small scale, retrieving device outputs and storing them for compliance or troubleshooting works well. As enterprises grow to thousands of devices, predictable challenges emerge:
- Vendor-specific CLI inconsistencies
- Software version changes altering output formats
- Repetitive configuration snapshots stored daily
- Telemetry data overwhelming primary databases
- Slow compliance and audit queries
- AI systems struggling with noisy or inconsistent inputs
- Data is collected — but not normalized.
- Stored — but not optimized.
- Retained — but not governed.
Over time, storage grows faster than insight. Automation pipelines slow down. Analytics becomes unreliable. AI initiatives fail to deliver value. The issue is not the volume of data. It is the absence of intentional design.
From Raw Outputs into Engineered Data
A scalable framework treats network data as a lifecycle rather than a byproduct. The transformation must be structured and deliberate:
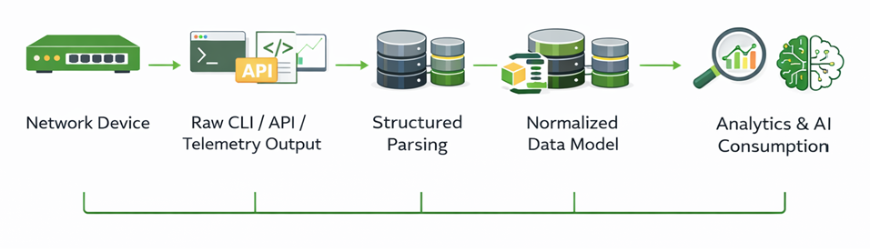
Parsing converts raw text into structured objects (machine-readable data).
Normalization ensures vendor-neutral consistency (uniform cross-vendor view).
Optimization ensures only meaningful information persists (cost and efficiency control).
This separation prevents downstream systems from compensating for inconsistencies and enables automation to scale predictably (operational stability).
Consistency is a prerequisite for intelligence (reliable AI outcomes).
Engineering Data Before It Is Stored
One of the most common architectural mistakes is storing everything “just in case.” While it appears safe, it leads to exponential growth in storage and degraded system performance.
A scalable framework refines data before persistence:
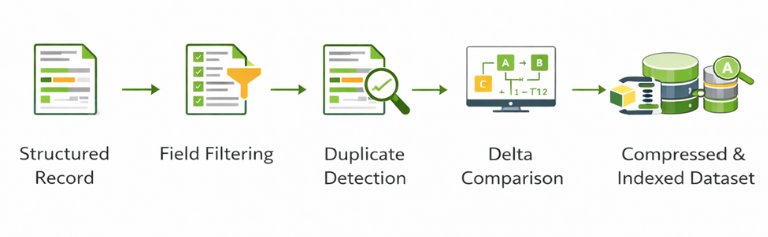
How This Works in Practice
- Field Filtering: Only operationally significant attributes are retained. Decorative CLI banners, transient debug lines, and non-actionable fields are excluded.
- Duplicate Detection: A deterministic hash is generated from key attributes. If the record matches the previous version, the system updates verification metadata instead of storing a new entry.
- Delta Comparison: Configuration history stores only changes relative to a baseline snapshot, preserving full auditability while dramatically reducing storage consumption.
- Compression & Indexing: Clean records are compressed and indexed by device ID and timestamp, enabling fast retrieval at scale.
This approach converts raw device output into engineered, query-ready data.
Real-World Example 1: Configuration Drift at Enterprise Scale
Consider an enterprise managing 1,200 switches, each with approximately 400 interfaces. A daily compliance job captures interface configurations.
Without optimization, full snapshots are stored every day:
- 1,200 devices
- 400 interfaces per device
- 365 days of storage
Millions of largely identical records accumulate annually.
In a scalable framework:
- Device configurations are parsed and normalized into structured JSON.
- Only compliance-relevant fields (e.g., mode, VLAN assignments) are retained.
- If today’s snapshot matches yesterday’s, no new record is written.
- If a VLAN changes, only the delta is stored.
Instead of repeatedly storing full configurations, the system captures only meaningful changes.
This enables the team to instantly answer questions such as:
- What changed before the outage?
- Which VLAN updates occurred last week?
- Where is configuration drift emerging?
The Storage footprint decreases significantly while visibility improves.
This is not just data storage. It is data engineering.
Real-World Example 2: Managing Regression and Automation Log Growth
Beyond device data, regression and automation logs introduce a parallel scalability challenge. In large enterprise environments running continuous regression pipelines, thousands of test cases generate execution logs daily. When verbose debugging is enabled, similar failure patterns may be stored repeatedly across runs. Without governance, automation logs can grow faster than configuration data—impacting storage costs, retrieval speed, and AI analysis accuracy.
A scalable framework addresses this by:
- Retaining full logs primarily for failures.
- Storing summarized records for successful executions.
- Grouping recurring failure patterns instead of duplicating verbose logs.
- Applying retention policies to debug-level data.
- Automation logs, like device data, must be engineered—not merely archived.
AI-Ready Indexing
Logs are parsed, tokenized, and indexed so AI systems can retrieve relevant failure context without scanning entire raw files.
By engineering regression log pipelines, enterprises prevent automation itself from becoming a storage burden.
Designing the Right Storage Strategy: Different types of network data require different storage mechanisms. A one-size-fits-all database strategy rarely scales.
Compliance Data and Metadata: Stored in relational databases for strong schema enforcement, indexing, and reporting efficiency.
Device State and Configuration Snapshots: Stored in document databases in structured JSON format, supporting hierarchical and nested data models.
Telemetry and Performance Metrics: Stored in time-series databases optimized for timestamped numerical data and aggregation.
Raw Logs and Historical Archives: Stored in compressed object storage for economical long-term retention. A hybrid storage model ensures performance, cost control, and scalability across years of operational history.
Managing Storage Growth as an Architectural Discipline
Storage saturation is often silent until performance degrades.
Without governance:
- Snapshots accumulate indefinitely
- Telemetry overwhelms primary databases
- Query latency increases
- Infrastructure costs escalate
Scalable frameworks enforce:
- Defined retention windows
- Tiered hot and cold storage
- Automated archival policies
- Data compression standards
- Capacity forecasting
Storage planning is not maintenance overhead — it is an architectural necessity.
Enabling AI-Driven Intelligence Through Structured Retrieval
AI is increasingly integrated into network operations for:
- Root cause analysis
- Anomaly detection
- Pattern recognition
- Intelligent summarization
However, AI systems are highly sensitive to input quality.
A well-designed retrieval model ensures that AI receives clean, contextual data:
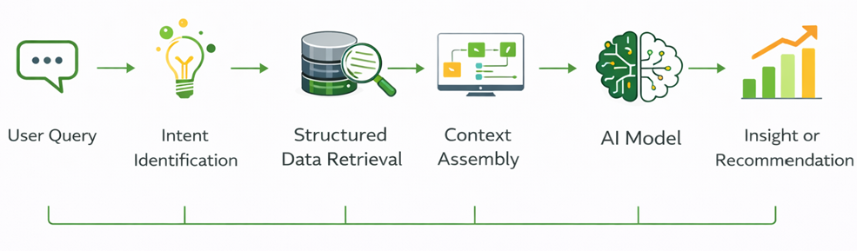
AI models perform reliably when provided with:
- Normalized JSON records
- Indexed change history
- Aggregated telemetry trends
- Clean metadata
Feeding raw CLI dumps directly into AI systems increases ambiguity and reduces accuracy. AI effectiveness is directly proportional to data discipline.
Business Outcomes of an Engineered Data Framework
Organizations that treat data collection as architecture rather than scripting achieve measurable improvements:
- Faster root cause analysis
- Reduced storage costs
- Improved compliance reporting
- Predictable automation scaling
- Reliable AI integration
Data transitions from an operational burden to strategic asset. Scalability becomes intentional rather than reactive.
The Role of Happiest Minds
At Happiest Minds, we combine networking expertise, data engineering practices, and AI capabilities to design sustainable automation ecosystems.
Our approach includes:
- Secure and scalable data acquisition frameworks
- Robust parsing and normalization strategies
- Optimized hybrid storage architectures
- Governance-driven retention models
- AI-ready data pipelines
We help enterprises move beyond isolated automation scripts toward architected data platforms that enable intelligent network operations.
Automation becomes durable when data is engineered with foresight.
Conclusion
Designing scalable data collection frameworks is not simply a technical task—it is a strategic enabler of intelligent network operations.
By transforming raw device outputs into structured, optimized, and AI-ready datasets, enterprises create automation systems that remain efficient, cost-effective, and insight-driven as they scale.
In the era of AI-driven intelligence, competitive advantage lies not in collecting more data—but in engineering better data.
Enterprises that engineer their data today will lead intelligent network operations tomorrow.

Sivaji Chandraiah is a Test Architect at Happiest Minds with over 13 years of experience in networking, enterprise validation, and scalable test automation frameworks. He specializes in architecting intelligent automation ecosystems using Python and pyATS for large-scale network environments.
He has led initiatives integrating AI agents and agentic AI architectures into automation workflows for failure analysis, intent-driven execution, dynamic test generation, and automated RCA summarization. His work focuses on building structured, data-driven validation platforms that enable intelligent and adaptive network operations.
Sivaji brings strong analytical depth and architectural rigor to designing resilient, scalable, and future-ready automation systems, and actively contributes to technical innovation and knowledge-sharing initiatives within the organization.





