
In the past year, GenAI has transitioned from experimentation to reality. What began as simple prompt testing and proof-of-concept chatbots has now transitioned to systems that support real business workflows.
However, while building our GenAI knowledge engine: a system that reads hundreds of PDF pages, creates embeddings, and answers enterprise questions, it became apparent that LLM systems were no longer being prototyped. They had simply become a business-critical system.
Today, LLM workloads drive customer support, summarizing legal documents, processing internal reports, and directly integrating into operational business workflows. When these systems fail, it’s no longer a minor issue – it breaks processes, impacts decision-making, and erodes trust. This is why resiliency has become a fundamental design principle for any serious GenAI system.
What Multi-Region Actually Means in Azure’s LLM World
Most people think of multi-region Azure OpenAI as a simple concept: deploy to two regions, and you’re good to go. However, it’s much more nuanced than that.
To understand what multi-region actually means in Azure’s LLM world, the starting point is to understand the Azure OpenAI Resource.
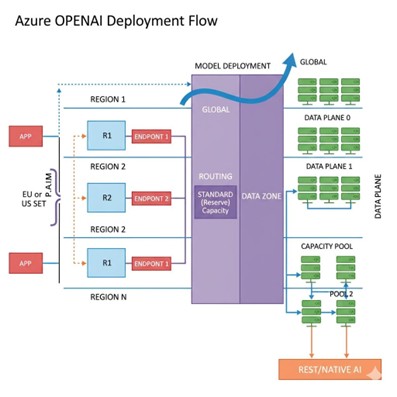
When you develop an Azure OpenAI resource, such as in East US, South Central US, and so on, that resource is permanently locked to that region. It doesn’t move, fail over, or route traffic through any another region. Deploying a model doesn’t mean it’s multi-region; your endpoint is still regional.
Inside the Region: Your Model Isn’t Running Where You Think. Even though your endpoint is in one region the model itself doesn’t mean sit behind that URL like a traditional app server.
Within each Azure OpenAI region:
- Huge capacity pools run the actual model variants (e.g., GPT-4.x, GPT-4o, text-embedding-3-large).
- Each pool consists of many GPU-generated VMs, sometimes tens or hundreds depending on model size.
- Pools autoscale based on traffic.
- A control plane is constantly monitoring health, spinning up new instances, and replacing failed ones.
So, what happens if one VM or model shared goes down? The request is simply served by another instance.
But if the Whole Regional Pool Fails, Your Deployment Fails with It. And this is the actual risk. This can occur in cases when:
- the whole capacity pool for your model version is down
or
- the region experiences a broader data plane problem
or
- the Azure OpenAI resource itself is affected
At this point:
- Your request can’t get to any model instance.
- Your deployment type (standard vs. global) doesn’t matter.
- Autoscaling won’t save you.
- Control plane repair won’t help.
If the regional endpoint is down, everything is down.
How Our Use Case Made Multi-Region Essential
When developing our GenAI knowledge engine, it was only natural that we broke down the system into two broad workflows. The first was a long-running ingestion and embedding workflow that could handle hundreds of pages from enterprise PDFs, extract them into structured chunks, and produce embeddings that were indexed in Elasticsearch. The second was a real-time question-answering workflow that could retrieve relevant chunks or data, produce context, and provide precise answers with citations.
As the system evolved, these two workflows became increasingly intertwined and increasingly important. The embedding pipeline helped ensure that our knowledge graph remained up-to-date and reflected the latest content. The real-time pipeline helped ensure that our users received answers to their queries instantly, accurately, and with contextually relevant detail. Over time, more and more workflows, automations, and agentic processes began depending on these two pipelines.
And it was at this point that architectural insight became unavoidable.
The nature of the system, with ingestion jobs running for hours, multiple concurrent users querying the knowledge engine, and automated tasks chaining LLM calls, meant that the system relied heavily on its LLM backbone.
Designing the Multi-Region Architecture
Azure OpenAI does not support automatic failover or global routing. Each deployment is strictly tied to the region in which it was created, which means that the application itself has to decide where to direct requests.
The first requirement was straightforward. We deployed the same models in a second region of Azure. However, the matching model names alone was not sufficient. The deployments had to act in a consistent manner so that the responses from Region A and Region B would be related in context and structure, even if the same responses were not expected or required.
With both regions ready, the real work was to build the application logic that could make region selection decisions. Response time delays, repeat request failures, unanticipated error messages, and inconsistent behavior are examples of indicators that the primary region might not perform normally.
The application should be able to act on these indicators by testing the secondary regions in the background assessing whether it was healthy and moving traffic when required. The motive is to make the transition seamless and transparent to users. When the conditions are normalized, the systems could gradually return to the primary region without interrupting ongoing activities.
In practice, our multi-region resilience has turned out to be less about having multiple deployments and more about enabling the application itself to route intelligently between them.
What We Actually Implemented: Primary-Secondary Region Failure
When we finalized the design, our multi-region approach became a straightforward and effective model: a primary region that handle all traffic under normal conditions and a secondary region that remain fully ready to take over whenever the primary cannot serve requests. The goal was to ensure that the knowledge engine never becomes dependent on a single Azure OpenAI endpoint.
If the system noticed pattern that the primary region wasn’t responding normally, it didnt immediately switch. Instead, it validated the situation by issuing light weight test calls to the primary region in the background. If all of the test calls fail after a defined amount of time, then switch to the secondary region and was carried out application updated its routing logic and moved all subsequent LLM requests to that region for the remainder of the workflow. The transition did not interrupt ongoing, and the rest of the RAG pipeline continue to use the available healthy region.
Once the application had switched to the secondary region it remained there on confirming that the primary region is again healthy. To validate this, system periodically issued small background health-check calls from time-to-time. Only when those calls return consistent thus the routing return to the primary region. Everything happened quietly without user interaction or ingestion cycles, nor causing unnecessary oscillation between regions.
What we effectively achieved was a set up where the application doesn’t depend on Azure to manage resilience. Instead the application itself becomes responsible for deciding which region to use based on real time signals rather than assumptions. As a result, the entire pipeline (from embedding, to retrieval, to final generation of the answer) tolerant to regional variability while maintaining consistent behavior and response quality.

Cost Vs Resiliency Trade Off
An important realization during our design phase, was that multi-region resiliency for Azure OpenAI doesn’t follow the conventional double the region, double the cost assumptions. Azure does not charge for creating a second deployment or maintaining an additional endpoint in the same subscription. The only meaningful cost driver is token usage. This means the secondary region incurs almost no cost until it is actually used.
The only added overhead comes from the very light health check ups that contribute to lightweight token consumption. Even under continuous polling this overhead is too small to materially impact the operational spending. The secondary region remains fully available but effectively dormant costing almost nothing until the system switches traffic to it during failover or elevated health checkup validation.
This changes the cost resilience equation significantly. Instead of choosing the higher availability and higher spend we found that we could achieve the strong multi region resilience with minimal incremental costs. For workloads that depend heavily on LLM inference, this model makes resilience far more accessible. You pay for the tokens you consume, not for the safety net itself.
Monitoring and Compliance in a Multi-Region LLM Architecture
Multi-region resilience is not only about routing traffic between regions. Observability and compliance become equally important as requests begin flowing across geographical boundaries.
From monitoring perspective teams can compliment application level health checks with Azure native observability tools. Platform metrics such as request latency, error rates, throttling events, and service availability can provide early visibility into regional degradation and help distinguish transient issues from broader service instability. These signals are often used alongside application logic to inform operational decisions and post incident analysis.
Multi-region architecture also introduces compliance considerations particularly when user queries and conversation context may be processed in more than one region. While inference requests are typically transient and not persisted by the platform, organizations still need clarity on where processing occurs, how logs are retained, and which are permitted for handling sensitive data.
With the scalability of GenAI, the resilience decisions intersect with the governance. Designing for availability has to align with transparency and observability and comply with organizational requirements when operating across regions.
Conclusion
While GenAI moves from experiments to production- grade infrastructure, the resiliency stops being nice to have and becomes a fundamental design component. As soon as LLM is integrated into a workflow (e.g., retrievals, decision-making, document processing, customer interactions), it inherits all expectations of availability and stability that an enterprise system demands.
A multi-region architecture is a natural progression of that transition. Azure OpenAI resources are inherently regional, relying on a single region creates a single point of failure. By distributing deployment across regions and allowing the application to route intelligently between them, you transform fragile dependency into a resilient foundation.
This evolution marks the point where Gen AI leaves the lab demo phase behind. Once resilient system is engineered into the system; Gen AI stops being an experiment and production infrastructure, stable predictable and capable of supporting real enterprise workloads.
Multi-region is not an upgrade in current landscapes today
It is a baseline for serious AI system built for an enterprise.

A Data Scientist at CoE Analytics, has a specialization in AI and Platform Engineering, with a focus on building intelligent, scalable systems using large language models, cloud-native architectures, and data-driven automation. She has experience across the end-to-end lifecycle of AI solutions—from problem framing and model development to evaluation, deployment, and continuous optimization.
She believes that responsible AI, strong system design, and close alignment between data, models, and business intent are essential to building trustworthy and transformative intelligent platforms.





